
Evals in Agentic Workflows: A Practical Guide
The art of evaluations changes dramatically depending on your system’s maturity and agentic complexity.

Howdy, with some recent conversations i wrote those notes to share my process on WHEN to use monitoring and evals in your agentic systems/apps. Curious to hear your thoughts in the comments. What has worked best for you recently?
Here is my current playbook.
Early Stage: Simple Agentic Features Monitoring
When shipping a v1 feature, I recommend using Opik (Comet) during development only—not in production yet. The reasoning is simple: traces let you methodically review what you’re building. Think of it like ML engineers iterating on accuracy, recall, and F1 scores. This methodical approach accelerates reaching the right behavior faster.
Speed > all the other “moats” in the first place. Focusing on measuring user engagements and early feedbacks.
At this stage, prioritize achieving your expected outcome first. Then reverse engineer from cost, volume, and other requirements. That said, when you do ship to production, implement guardrails and save everything to your database for future analysis.
Advanced Stage: Complex Agentic Systems Evals & Iteration
When a significant part of your software is agentic, consider these approaches:
Continue using Opik for monitoring improvements and catching new edge cases.
Build evals. Think of evals as CI/CD tests for your agents. They verify your system performs as intended across common use cases and edge cases. When building on top of existing prompts or changing behaviors, evals ensure you can: 1) detect if something broke, and 2) easily revert through prompt versioning (your own system or a tool link opik).
This becomes critical for complex agents with tools, multi-agent systems, and cost optimization.
Infrastructure choices: Either self-host a tool like Opik for production logs, prompt versioning, and evals—or build your own system using PostgreSQL for prompt versioning and trace storage that enables better investigation later. Think from your solution and no existing tech stack recommended by your fav. influencer.
Key Evaluation Principles
Avoid model-generated scores. They’re inherently non-deterministic. Having ChatGPT rate something 5/5 isn’t meaningful. Instead, create multiple boolean rules to assess threads, answers, or behaviors. This approach is also valuable when fine-tuning or distilling models to make sure they perform as intended for your use cases. Or even building analytics with llms.

Don’t optimize prematurely. If you haven’t found v1 adoption or your system doesn’t need added complexity, wait. Optimize what delights users first.
As Hamel Husain writes, model-based scoring is “The 5-Star Lie.” Build deterministic evaluations instead. Check Decoding AI Magazine and The Neural Maze for more in depth content on all this. They’re the best places to learn from rn.
Optimizing for Costs and Performance
Once you’re ready to optimize, explore:
Memory and caching strategies
Cheaper models fine-tuned for specific behaviors (or distilling etc.)
Simplified decision paths that maximize expected outcomes
Training your own llm (just kidding)
The evolution from simple to complex agentic systems demands different evaluation strategies. Start methodical, ship with guardrails, and optimize what proves valuable.
More on this with Paul Iusztin:
Also check this project to learn more on this with Paul Iusztin and Miguel Otero Pedrido: Philo Agents GitHub Repo.
On another aspect, when you design user experience with agentic behaviors, it’s crucial to experiment with new engaging feedback loops without text inputs. Creating delight experiences guiding towards expected outcome intuitively, like you KNOW the user thought process so well that you remove any complexity. That’s what matter the most. Or one of the most important things at least.
My intent with this short post is not to tell you the HOW but to give you a proper understanding of when you need to think about adding these pieces into what you’re building.
Make sure you create value (time saved, revenue generated, users delighted), build efficiently using Opik or any tool you prefer to reach your goal, log the most important things in your database, build features that allow you to get feedback from your users as you improve, then build further.
And finally, create your evals when necessary. For example: a new model that will do tool calling in a subpart of your agentic process, or classification on a dataset that must be accurate.
When you’re optimizing for the above and the volume of requests to your system increases, start implementing cheaper models and efficiently using other techniques like ensuring caching and memory are handled smartly.
Traces are superior to logs especially in the IDE where your terminal is limited in context and you loose previous logs the limit is reached.
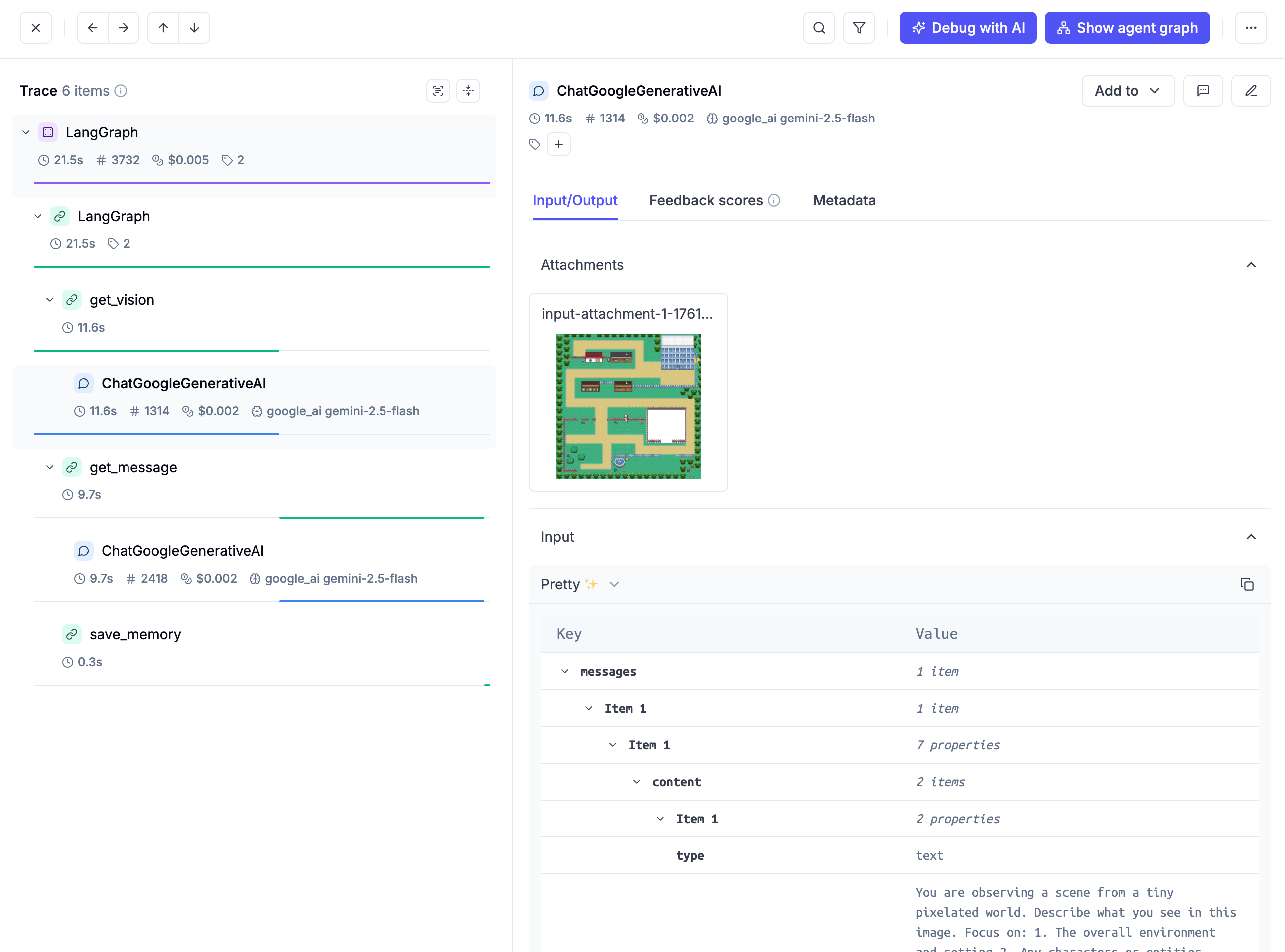
Fun fact. I know that some people have been surprise by seeing that the trace in Opik also logs images passed to the models. Yes it tracks costs per providers too. And more cool things.
Do what works best for your use cases and be methodical about it. Learn, improve, iterate. Resource allocation must be your super power.
Now go build :)
Thanks for the shout-out 🤟