
Reading the GPT Papers (1,2,3,4)
Claude 4.6 drops, Amp kills their editor, Sam and Dario not holding hands, but let's go back to GPT-1, GPT-2, GPT-3, GPT-4. Just for fun.

While Peter Steinberger joins OpenAI (vs Anthropic),
Anthropic drops Claude 4.6 and restricts OAuth,
Alibaba unveils Qwen 3.5 with 397B parameters, and Sam Altman and Dario Amodei refuse to hold hands at an AI summit in India,

I decided to revisit the gpt papers GPT1, GPT2, GPT3, GPT4 papers.
tl;dr
GPT-1 (2018): Proved Transformers transfer. Pre-train on BooksCorpus, fine-tune for tasks. 12-layer decoder. 9/12 benchmarks beaten. GLUE score 72.8. The seed of something big.
GPT-2 (2019): Skip fine-tuning entirely. 1.5B parameters on WebText. 55 F1 on CoQA zero-shot. Log-linear scaling validated. Model still underfitting. Translation: make it bigger.
GPT-3 (2020): 175B parameters. In-context learning. Zero-shot, one-shot, few-shot. No gradient updates. Autoregressive limitation. Data contamination emerges. Bar exam bottom 10%.
GPT-4 (2023): Predictable scaling at 1/10,000th compute. Multimodal. RLHF aligned. 24/26 languages on MMLU. Bar exam top 10%. Still hallucinates. Still not fully reliable.
GPT-1: The Foundation (June 2018)
“Improving Language Understanding by Generative Pre-Training”
This paper proved one thing: Transformers transfer.
Before GPT-1, if you wanted a model to do sentiment analysis, you trained a sentiment model. If you wanted it to answer questions, you trained a QA model. Each task required its own architecture, its own data, its own training run.
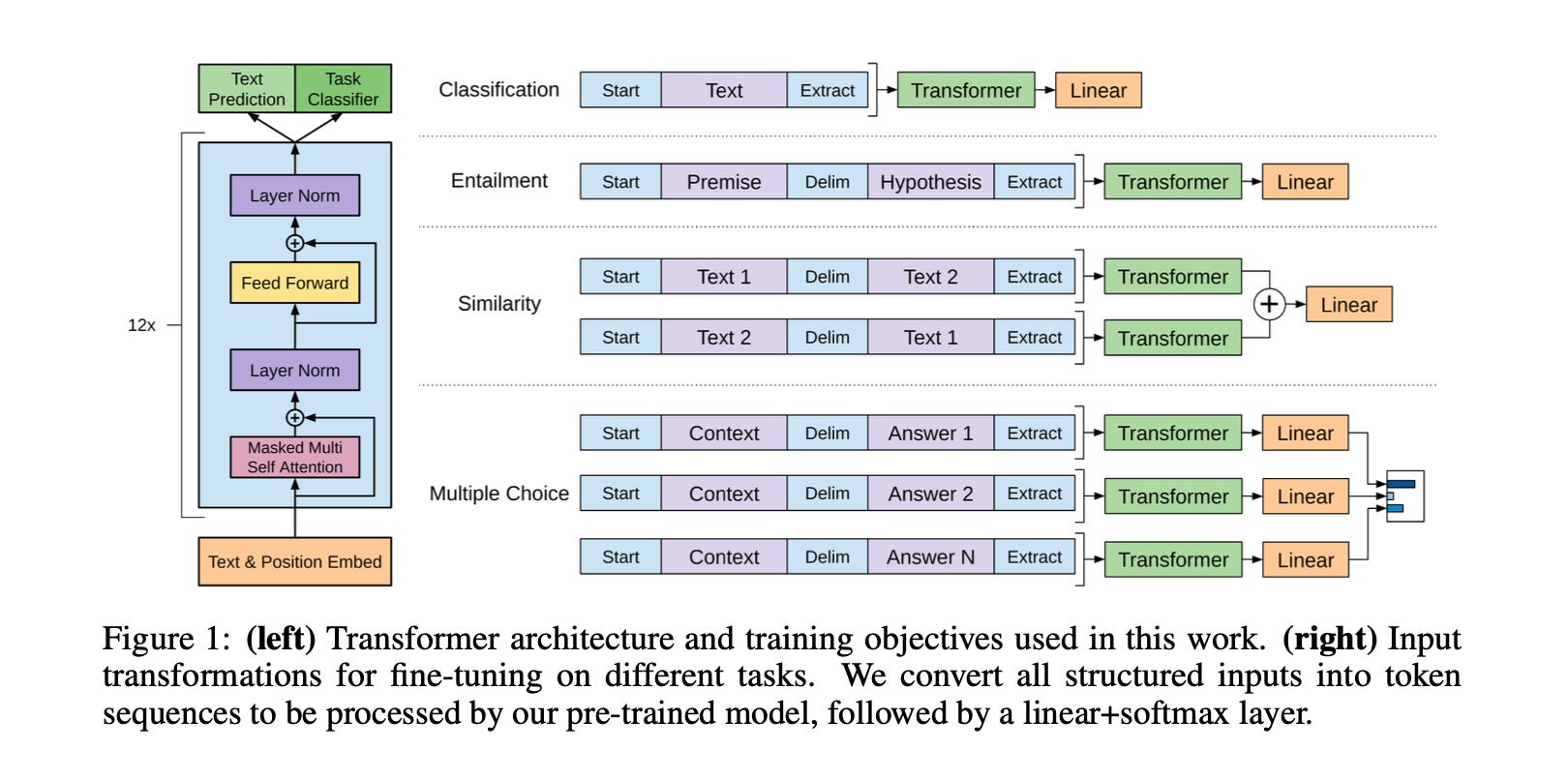
GPT-1 changed the game with a simple two-stage approach. First, pre-train a 12-layer Transformer decoder on BooksCorpus (4.5GB of books) to predict the next word. Then, fine-tune that same model on specific tasks by adding a small linear layer on top.
The key insight was the input transformation. Instead of building different architectures for different tasks, they reformatted all tasks into sequences the model already understood.
Classification: [Start] Text [Extract]
Entailment: [Start] Premise [Delim] Hypothesis [Extract]
Multiple Choice: [Start] Context [Delim] Answer N [Extract]
Same brain, different packaging.
The results: 9 out of 12 benchmarks beaten. +8.9% on commonsense reasoning (Stories Cloze). +5.7% on question answering (RACE). 72.8 on GLUE.
The pre-trained model already showed “zero-shot” capabilities before any fine-tuning. They planted a seed they didn’t fully understand yet.
GPT-2: The Zero-Shot Rebellion (February 2019)
“Language Models are Unsupervised Multitask Learners”
GPT-2’s rebellion was refusing to fine-tune.
The hypothesis: if a model is big enough and trained on diverse enough data, it will automatically learn to do tasks without explicit training. They called this “meta-learning” through language modeling. The internet contains naturally occurring demonstrations of every task imaginable. Someone, somewhere, has written “I hate the word ‘perfume,’ Burr says. ‘It’s somewhat better in French: parfum.’” A model predicting the next word on that sentence accidentally learns translation.

They scaled to 1.5B parameters (13x GPT-1) and trained on WebText, 40GB of internet text scraped from Reddit links with at least 3 upvotes. Quality filter built into the data source.
The results validated the hypothesis. 55 F1 on CoQA (reading comprehension) without seeing a single training example. 7 out of 8 benchmarks beaten in zero-shot mode. The blue line in every graph goes up as parameters increase.
The paper notes that the 1.5B model “still underfits WebText.” The model was too small to learn everything in the dataset. Make it bigger and it gets smarter. This validated the scaling law that would define the next five years of AI.

GPT-3: The Few-Shot Moment (May 2020)
“Language Models are Few-Shot Learners”
GPT-3 introduced the vocabulary we use today.
Zero-shot: instruction only, no examples. “Translate this to French: cheese =>”
One-shot: instruction plus one example.
Few-shot: instruction plus 10-100 examples in the prompt.
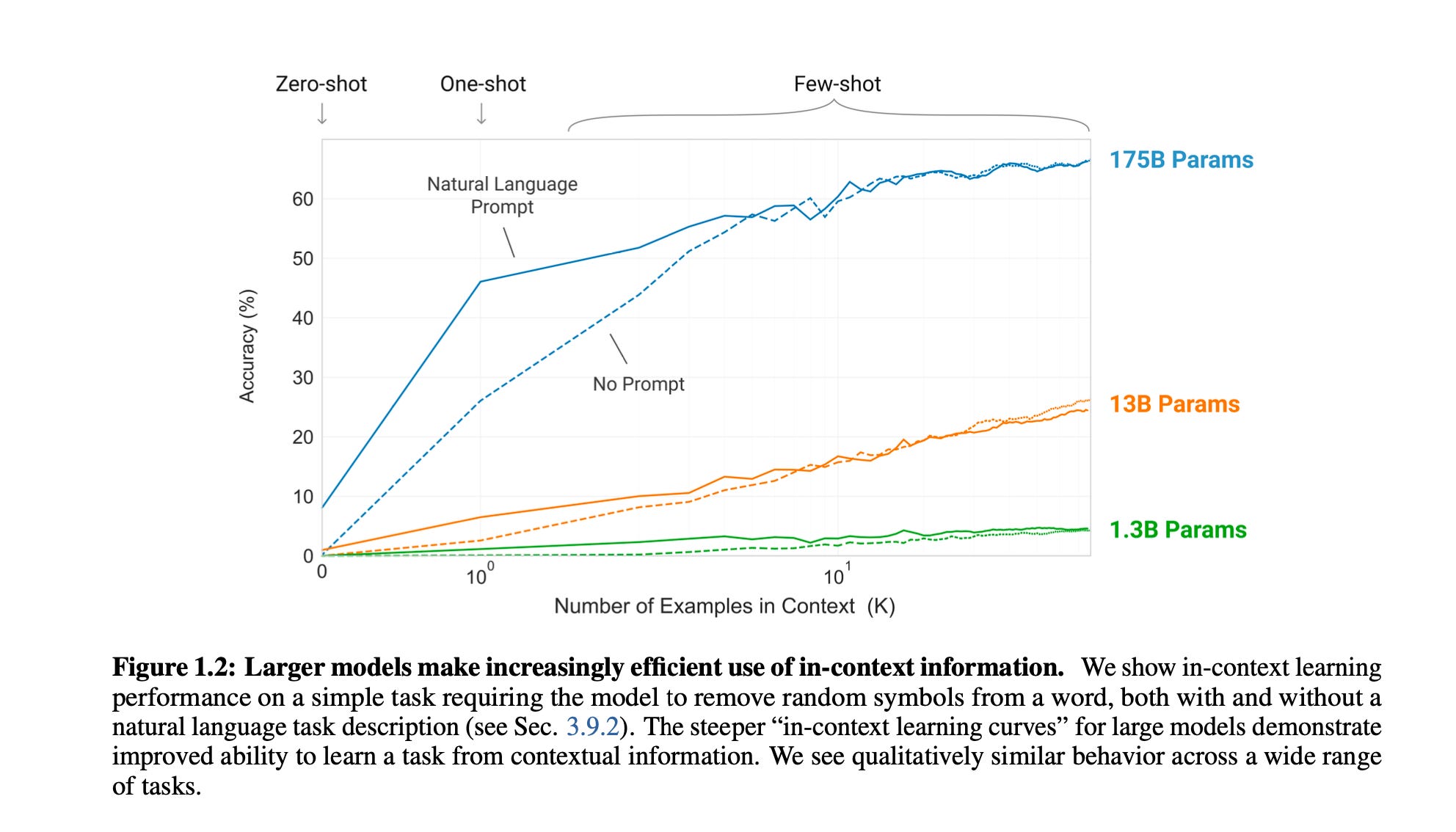
The critical nuance: none of this updates the model’s weights. The “learning” happens entirely in the context window. They called it in-context learning. The model isn’t learning new information; it’s recognizing which skill from pre-training to apply.
At 175B parameters (117x GPT-2), the model became dramatically more efficient at using context. The slope of the learning curve for the 175B model is steeper than the 13B model. Bigger models don’t just know more; they figure out what you want faster.
The paper also admitted structural limitations. GPT-3 is autoregressive (reads left-to-right only). Models like BERT are bidirectional (see the whole sentence at once). For tasks requiring comparison or re-reading, the left-to-right constraint is a disadvantage. NLI and ANLI remained weak spots.
And then there was data contamination. When you train on the entire internet, you might accidentally train on the test. This paper broke the old benchmarks by memorizing them. The field had to invent new evaluation methods.
GPT-3.5 would later score in the bottom 10% on the Bar exam. The foundation was set.
GPT-4: The Predictable Leap (March 2023)
“GPT-4 Technical Report”
GPT-4’s breakthrough wasn’t just being smarter. It was being predictably smarter.
They developed infrastructure that predicted GPT-4’s final performance using models trained with 1/1,000th to 1/10,000th the compute. Before training the full model, they knew roughly how well it would perform. This gave the industry confidence to spend billions on even larger models because they could forecast ROI.
The capability jump was dramatic. GPT-3.5: bottom 10% on the Bar exam (213/400). GPT-4: top 10% (298/400). Same underlying architecture, more scale, better alignment.
GPT-4 added multimodality (images and text in, text out) and dominated multilingual benchmarks. On MMLU (57 subjects), it outperformed English-language SOTA in 24 of 26 languages tested, including Latvian and Welsh.
Safety became a first-class concern. They used RLHF (Reinforcement Learning from Human Feedback) and introduced RBRMs (Rule-Based Reward Models), essentially using GPT-4 to make GPT-4 safer. Recursive.
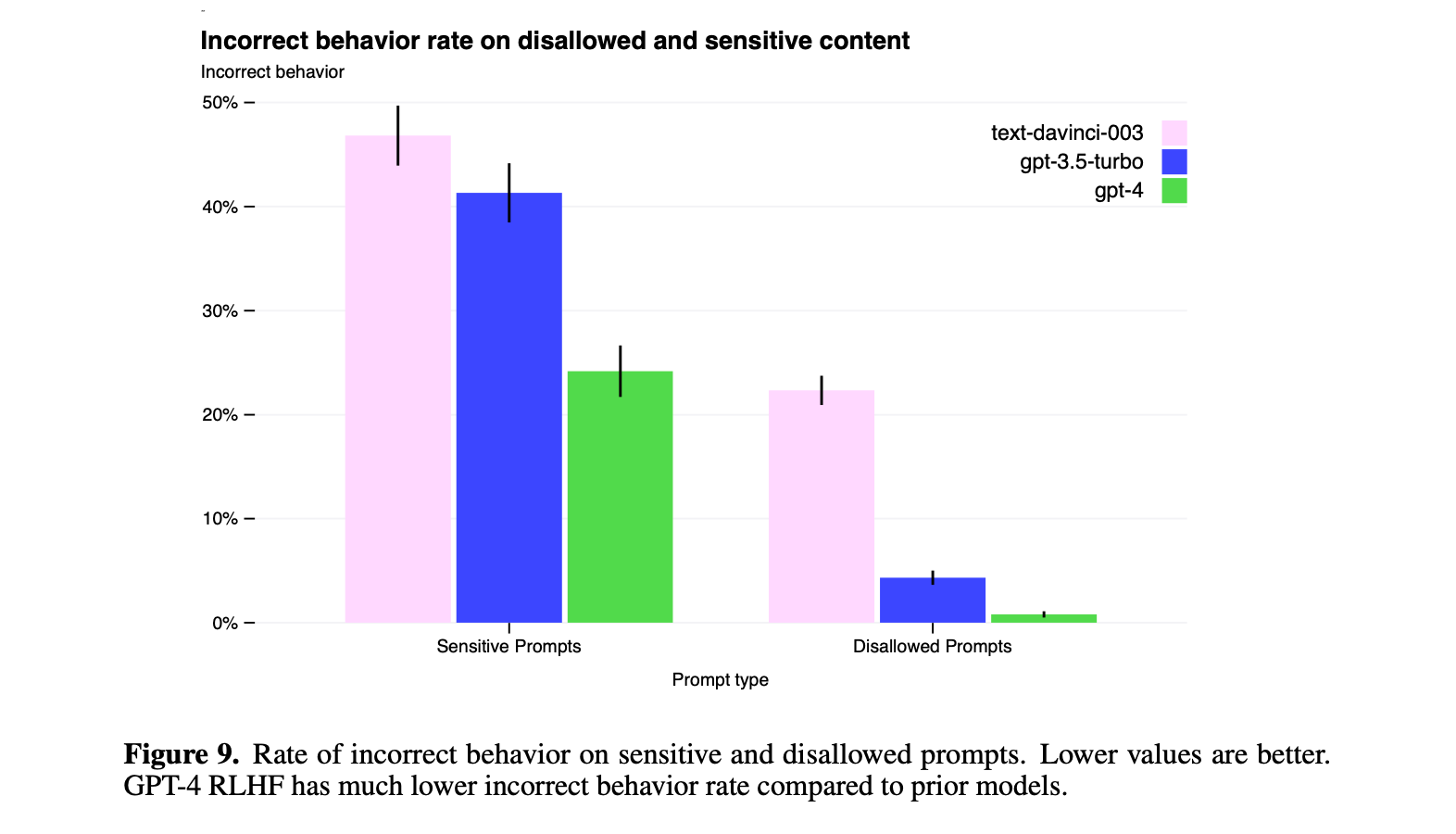
But the paper is honest about limitations. Hallucinations persist. Knowledge cuts off at September 2021. The model is “not fully reliable.” Jailbreaks still work.
The incorrect behavior rate dropped dramatically from text-davinci-003 to GPT-4. Progress, but not perfection.
The Takeaway
The architecture hasn’t fundamentally changed since 2017. It’s still Transformers predicting next tokens.
What changed:
Scale: 117M to 175B+ parameters.
Data: Books to internet to curated internet.
Paradigm: Fine-tune to zero-shot to in-context learning.
Alignment: Raw outputs to RLHF to model-assisted safety.
The burden of adaptation shifted from developers to models. We used to train models for tasks. Now we describe tasks to models.
A few words I’m hearing constantly these days: “recursive” and “hierarchical.” Recent publications on harnessing the context window are scoring high on benchmarks and getting a lot of attention (some question the real progress in this publications). From a recent paper club, Raphael Kadandaze presented two papers on Recursive Language Models.
Meanwhile, Amp removes their VSCode fork to focus entirely on CLI. The bet: AI-native interfaces don’t need to look like traditional IDEs.
It was fun with all the hype to read this serie of papers, and if you look at the authors in each you re-live all the evolution of openai. e.g. you see Ilya on the first paper, then Dario on GPT-2 and it continues.
Coming back to the present, what are your best reads recently?